Microscopic Image Labeling: Identifying Cells, Organelles, and Pathogens
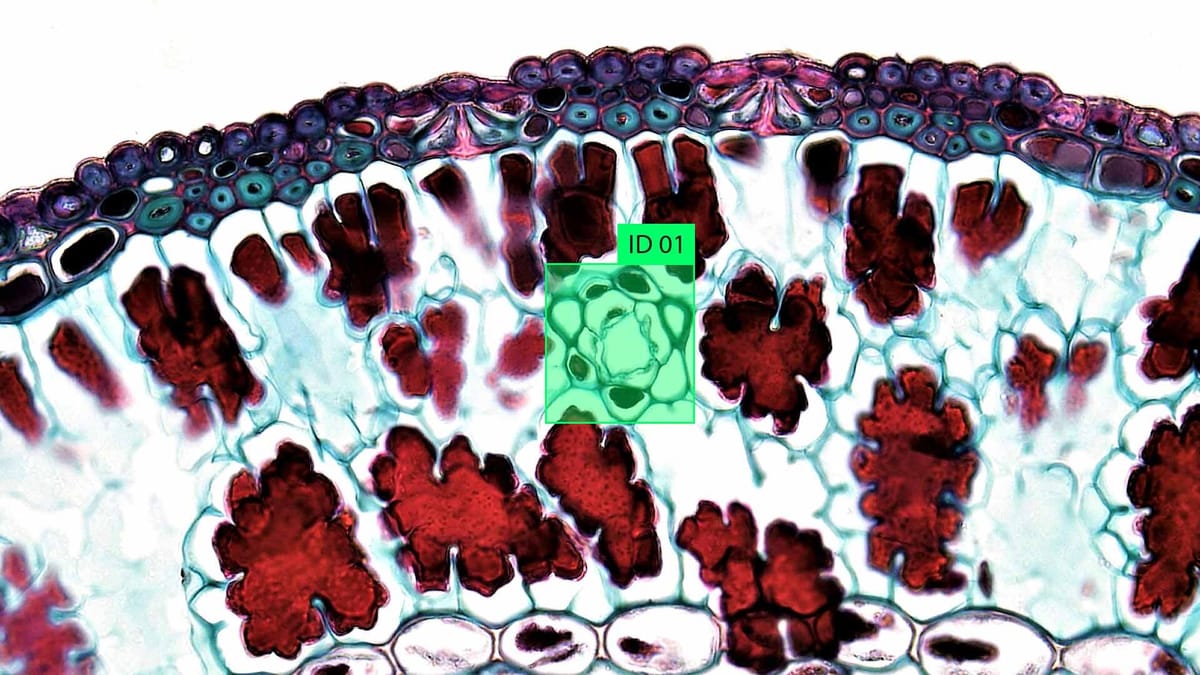
Microscopic image labeling plays a key role in modern biological and medical research, offering a way to transform raw visual data into useful scientific information. Thanks to advances in imaging technology, scientists can now obtain incredibly detailed images of cells, organelles, and even microscopic pathogens. However, these images are only as useful as the information we can extract.
Labeling of microscopic images is essential in many fields. It supports cell biology by mapping cell types or organelle distribution. In medicine, it is used to detect pathogens in samples or monitor disease progression at the cellular level. Drug development also benefits researchers because they can track how a treatment affects cells. Much of this visual data would be difficult to interpret or quantify without accurate labeling.
Key Takeaways
- Hybrid annotation systems combine expert validation with crowdsourced scalability.
- Feature visualization tools like UMAP enhance cross-dataset compatibility.
- Precision labeling directly impacts diagnostic accuracy in pathogen detection.
- Advanced architectures (YOLO, Faster R-CNN) require structured training data.
Introduction to Microscopic Image Labeling
Microscopic image labeling assigns a value to specific areas or structures in images captured with microscopes. This often includes identifying and delineating cells, organelles such as mitochondria or nuclei, or foreign agents such as viruses and bacteria. Labeling uses annotation software, where users manually label objects or apply algorithms that automatically detect features. In research, labeled images are used to train machine learning models that can analyze new images without human intervention. In practice, this speeds up laboratory workflows, improves healthcare diagnostic tools and supports high-throughput research in biotechnology.
Essential Microscopic Cell Annotation Techniques
Microscopic cell annotation involves labeling and categorizing structures in an image to prepare data for analysis, often in research, diagnostics, or training artificial intelligence models. Different methods are used depending on the purpose, type of microscopy, and sample complexity. Some methods prioritize accuracy and detail, while others are built for speed and large-scale datasets. The most effective annotations combine multiple methods or evolve as tools and datasets improve.
- Manual annotation is the simplest method. A trained human annotator uses software to track or label specific structures in an image. This is often done using bounding boxes, polygons, or pixel masks to identify cells, nuclei, or organelles. Although time-consuming, manual labeling provides the most accurate data about reality, especially for complex or rare features that automated systems may miss.
- Semantic segmentation. Semantic segmentation involves labeling each pixel in an image with a class, such as "cell," "background," or "core." This is usually done using algorithms but can be corrected or refined manually. It is beneficial for identifying common structures throughout an image and is commonly used to train artificial intelligence models for medical imaging and cell biology.
- Instance segmentation. Instance segmentation takes semantic segmentation one step further by separating individual cells or structures of the same class. For example, instead of labeling all nuclei as one class, each nucleus is assigned a unique identifier. This is important for counting cells, tracking movements, or studying cell interactions in time-lapse images.
- Annotation of key points. Instead of labeling entire structures, keypoint annotation involves identifying and labeling specific points of interest, such as cell centers, mitotic spindles, or organelle tips. This is useful for cell tracking, morphometric analysis, or training models for cell-level pose estimation.
- Automated pre-labeling using artificial intelligence. Machine learning models can pre-label images by recognizing patterns based on pre-annotated data. Humans can then correct these pre-labels, which significantly speeds up the annotation process.
Core Principles and Terminology
Microscopic cell annotation is guided by a few foundational principles that ensure the data produced is accurate and useful across research and clinical applications. These principles center on consistency, precision, and clarity. The annotation must clearly define the boundaries and identity of each cellular feature while maintaining reproducibility across different users and datasets. Whether the task is identifying a single cell type or labeling thousands of structures in high-throughput experiments, these core ideas form the basis for reliable image interpretation and analysis.
- Accuracy refers to how well an annotation matches the actual structure in the image. Even slight errors in labeling, such as misplacing a boundary or confusing two cell types, can significantly affect downstream analysis. Annotators often rely on high-resolution images and clear labeling protocols to maintain accuracy.
- Consistency ensures that similar structures are labeled the same way across different images and annotators. This is critical in large-scale datasets and collaborative studies. Standardized guidelines or controlled vocabularies are often used to avoid confusion and reduce variability in labeling.
- Resolution plays a key role in determining how detailed an annotation can be. High-resolution images allow for fine-grained annotations of small structures like organelles or bacterial features. Low-resolution images may require more general annotations, focusing on larger structures like entire cells or tissue regions.
- Class or label refers to the category assigned to a structure, such as "nucleus," "cytoplasm," or "mitochondrion." In more advanced systems, labels can also include metadata such as cell phase, health status, or pathogen type. These labels are used to train machine learning models and perform quantitative analysis.
- Mask is a common term for the pixel-level representation of an annotated object. A mask highlights a structure's exact shape and position in the image. These masks are used in segmentation tasks and allow for precise measurement of size, shape, and spatial relationships between components.
Benefits of Biomedical Research
Biomedical research, mainly when supported by tools like microscopic image labeling, drives significant advancements in understanding human health and disease. It provides the foundation for discovering how cells, tissues, and systems function at a microscopic and molecular level. This research helps scientists uncover the mechanisms behind illnesses, from viral infections to genetic disorders, leading to more targeted and effective treatments. By studying cells and pathogens directly through labeled images, researchers can identify early signs of disease, track progression, and monitor how the body responds to therapies. The insights gained from this research continue to improve diagnosis, prevention, and personalized medicine.
Another significant benefit is drug discovery and development. Biomedical research enables scientists to test how drugs interact with cells, organelles, and pathogens in controlled environments. Microscopic image labeling helps pinpoint cellular responses, such as how a drug affects the nucleus or whether it disrupts a pathogen's life cycle. This shortens the timeline for finding promising compounds and reduces the risk of failure in later clinical trials. With precise labeling, researchers can run high-throughput experiments, screen thousands of drug candidates, and collect detailed data to guide decisions.
Beyond medicine, biomedical research also contributes to broader scientific knowledge and innovation. It supports advances in biotechnology, regenerative medicine, vaccine development, and environmental health studies. For example, understanding how bacteria adapt under stress can lead to new antibiotic strategies or reveal how microbes affect ecosystems. With high-quality annotated datasets and modern analysis tools, biomedical research is becoming faster, more data-driven, and more impactful than ever.
Crowdsourcing Platforms and Their Role
Crowdsourcing platforms have become valuable tools in microscopic image labeling, helping researchers process large volumes of data that would otherwise take months or years to annotate. These platforms connect a distributed workforce of contributors with tasks that involve identifying and labeling cells, organelles, or pathogens in microscopic images. Tasks are broken into small, manageable pieces to ensure accuracy, and the results are often reviewed or aggregated to filter out errors.
Preparing Your Microscopy Images for Annotation
Before you can begin annotating microscopy images, they need to be carefully prepared to ensure clarity, consistency, and usability. The quality of this preparation directly affects how accurately cells, organelles, or pathogens can be labeled and analyzed. Raw microscopy data often contains noise, uneven illumination, or overlapping structures that can make annotation more difficult. To avoid these issues, images are typically cleaned, standardized, and organized before being sent to annotators or fed into automated systems.
The first step is image preprocessing. Depending on the type of microscopy and the sample, this can involve background subtraction, contrast enhancement, and noise reduction. In fluorescence microscopy, for instance, filters may be applied to separate signals from the background or to isolate specific channels. Cropping may also focus on regions of interest, especially in large field-of-view images. It's important that these adjustments preserve structural details and don't introduce artifacts that could mislead annotators or algorithms.
Next comes standardization. This includes resizing images to a uniform scale, aligning them properly, and converting them to consistent file formats such as TIFF or PNG. Depending on the annotation task, if you're working with multi-channel or 3D images, each channel or slice may need to be labeled or presented separately. Metadata such as magnification, staining method, and sample type should also be recorded and linked to each image to provide context.
Organizing the images is also key. Grouping similar images, naming files systematically, and creating clear folder structures helps prevent confusion and make large datasets easier to manage. This organization allows for smooth integration into annotation tools when using crowdsourcing or automation. Annotators can work more efficiently, and algorithms can be trained on cleaner, more consistent data.
Image Pre-processing and Quality Control
Microscopy images often suffer from uneven lighting, background noise, poor focus, or inconsistent contrast, especially when collected from different samples or across multiple sessions. Pre-processing corrects these problems, while quality control ensures that only the best images are used for annotation or analysis.
Pre-processing typically begins with noise reduction, which can be done using filters such as Gaussian blur, median filters, or more advanced denoising algorithms. These help smooth out unwanted variations while preserving edges and delicate structures. Background subtraction and illumination correction are often used to reduce artifacts caused by inconsistent lighting or autofluorescence, especially in fluorescent microscopy. Enhancing contrast or applying histogram equalization can make structures more distinct and easier to identify.
Strategies for Effective Cell and Organelle Identification
Navigating complex biological samples demands layered identification approaches. Our team developed multi-spectral analysis protocols that combine spatial pattern recognition with spectral unmixing. These strategies proved vital in recent glioma studies where traditional methods struggled to separate tumor cells from reactive astrocytes.
Visual and Marker-Based Differentiation
In microscopy image annotation, distinguishing between cells, organelles, or pathogens often relies on two main strategies: visual differentiation and marker-based differentiation. These approaches help annotators or algorithms recognize and classify different structures based on how they appear or are labeled during sample preparation. Each method offers its advantages and is often used together to maximize clarity and precision in complex biological samples.
Visual differentiation relies on natural contrast and morphology. Annotators use size, shape, texture, and spatial arrangement to separate structures like nuclei, mitochondria, or bacterial cells. For example, nuclei usually appear round and dense, while mitochondria are more elongated and scattered throughout the cytoplasm. Visual cues such as brightness, edges, and granularity are key in unstained or phase-contrast images. Experienced annotators can often identify features by sight alone, especially in high-quality images.
Marker-based differentiation involves fluorescent dyes, antibodies, or genetically encoded tags that bind to specific cellular components. These markers glow in specific wavelengths under fluorescence microscopy, allowing for easy identification of structures like actin filaments, lysosomes, or viral particles. Multi-channel images can show several markers at once, each in a different color, making it possible to label and track multiple components in the same cell.
Implementing Machine Learning in Microscopic Annotation
Machine learning has become a central tool in the annotation of microscopic images, transforming what used to be a slow, manual task into a more efficient, scalable process. Instead of relying entirely on human annotators to label cells, organelles, or pathogens, machine-learning models can be trained to recognize these structures based on patterns learned from previously labeled images. This automation allows researchers to process large datasets much faster, with consistent accuracy, and often with less manual labor involved in the long term.
The process usually begins with a well-curated set of labeled images—often called the training data. These images are manually annotated or through a hybrid system combining expert input with crowdsourced labels. The labeled dataset is then used to train a model commonly based on convolutional neural networks (CNNs) for image recognition tasks. These models learn to detect the shapes, textures, and patterns associated with different cellular components. Once trained, the model can be applied to new images to perform segmentation, classification, or object detection tasks.
Using YOLO and Faster R-CNN Approaches
Object detection models like YOLO (You Only Look Once) and Faster R-CNN are popular for identifying and localizing structures such as cells, nuclei, and pathogens in microscopic image annotation. These models offer different advantages in speed, precision, and use case flexibility, making them suitable for various annotation tasks depending on the project's goals. Both approaches work by drawing bounding boxes around objects of interest and assigning them class labels. Still, they differ in how they process images and trade-offs between speed and accuracy.
- YOLO is a single-stage detector that looks at the entire image once and predicts bounding boxes and class probabilities in a single forward pass. This makes it extremely fast and ideal for real-time applications or large-scale datasets where annotation speed matters. In microscopy, YOLO is often used to detect larger, well-separated objects like individual cells or parasites. It's less effective when objects are tightly clustered or have subtle boundaries, but newer versions (like YOLOv5 or YOLOv8) have improved the handling of small and overlapping objects.
- Faster R-CNN, on the other hand, is a two-stage detector. First, it proposes regions of interest (ROIs) likely to contain objects, then refines and classifies those predictions. This two-step process allows for more precise localization and better performance with small or complex objects, making it ideal for crowded cell images or situations where high accuracy is essential. However, it's slower than YOLO and requires more computational power, which can be a limitation in high-throughput workflows.
These models can be trained in microscopy using custom datasets where cells or organelles are annotated with bounding boxes. The training process involves feeding the model-labeled images and optimizing them to minimize errors in localization and classification. Once trained, the model can automatically annotate new images, significantly speeding up the workflow. Post-processing steps—like applying threshold filters or merging overlapping boxes—can help clean up predictions for better final outputs.
Training with Consensus Labels and Data Variants
Aggregating annotations from multiple annotators or sources generates consensus labels. When annotators work on the same dataset, there's often some disagreement, especially in complex or ambiguous cases. By combining the labels of multiple annotators, consensus labeling aims to capture the most likely and accurate label for each object. This can be done through methods like majority voting, where the label that appears most frequently across all annotators is chosen, or more sophisticated approaches like weighted voting, where certain annotators' labels are given more importance based on their expertise.
Data variants are sometimes used to create a more comprehensive training dataset. Data variants refer to variations in the dataset, such as different imaging conditions, sample types, or treatment states. These variants ensure the model is exposed to a wide range of conditions, improving its ability to generalize and perform well on unseen data. For example, if a model is trained only on images of healthy cells, it may struggle when presented with images of cells affected by a disease. By including variants such as different disease stages or different types of microscopy (e.g., confocal, phase-contrast), the model becomes more adaptable to variations in real-world data. Data augmentation techniques, like rotating, zooming, or adding noise to the images, can also artificially increase the dataset's variability, further improving model robustness.
Image Representation and Pre-trained Model Utilization
Image representation refers to how the raw pixel data from an image is processed into features that the model can use. The raw pixel values are usually too complex for direct analysis by machine learning algorithms, so they are transformed into higher-level representations such as feature maps or embeddings. In convolutional neural networks (CNNs), for example, early layers automatically extract low-level features like edges and textures, while deeper layers capture more complex patterns and object structures, such as cell membranes, organelles, or pathogens. This hierarchical representation is crucial for detecting fine details in microscopic images and differentiating between similar-looking structures. To improve representation, pre-processing techniques like histogram equalization, noise reduction, and contrast adjustment are often used to enhance image quality before feeding it into the model.
Analyzing and Aggregating Annotation Results
- Evaluation involves measuring the quality of annotations against ground truth or expert-defined labels. Metrics such as accuracy, precision, recall, and F1 score are commonly used to quantify how well the annotations match the actual structures in the image. For instance, in object detection tasks, intersection over union (IoU) assesses how well the predicted bounding boxes align with the actual objects. These metrics can be applied to human-generated annotations and machine-generated predictions to determine the performance of annotators and algorithms. Evaluating annotation quality is critical because even minor inconsistencies in labeling can impact downstream analysis or model training.
- Error detection is a vital part of the analysis process. You can spot discrepancies, such as misidentified or missed objects, by comparing annotations from different sources (e.g., multiple annotators or different models). Techniques like majority voting or conflict resolution algorithms are used to flag these errors. For example, suppose two annotators disagree on the presence of a structure. In that case, it might be necessary to review the case manually or retrain the model with more diverse or balanced data in the case of automated systems. Identifying patterns in these errors can also point to everyday challenges, such as difficulty distinguishing between similar cell types or organelles.
- Aggregating annotation results combine multiple annotations into a single, unified representation. In crowdsourcing or multi-annotator scenarios, this can involve aggregating the labels from several annotators to create a consensus label. Methods such as majority voting, weighted voting, or probabilistic models are often used to generate these consensus labels. In machine learning, multiple model predictions can also be aggregated, with techniques like ensemble learning (e.g., bagging or boosting) helping to combine forecasts from different models for improved accuracy and robustness. Aggregation ensures that the final labels reflect a broad consensus, reducing the likelihood of individual errors skewing the results.
Challenges in Distinguishing Between Similar Cell Types
One of the main challenges is the morphological similarity between certain cell types. For example, different types of epithelial cells or similar stages of a cell's life cycle (e.g., G1 and G2 phases) can look very similar under a microscope. They may have identical shapes, sizes, or structures, which makes it difficult to differentiate between them based on visual cues alone. In some cases, even the presence or absence of specific organelles may not be enough to identify the cell type, especially if the cell is in an early or late stage of differentiation.
Another issue arises with overlapping features in crowded or dense cell cultures. Cells with overlapping membranes or indistinct borders can often appear near each other. This is especially true in highly packed tissues or multi-cellular layers, where the boundaries between cells can be blurry or merged. Accurate segmentation and differentiation of these overlapping cells require advanced image processing and precise annotation techniques, which can be challenging to achieve, particularly in noisy or low-resolution images.
Different microscopy methods, such as fluorescence, phase contrast, or brightfield microscopy, have varying levels of sensitivity and resolution, and some may not provide enough contrast to distinguish between closely related cell types. Fluorescent staining techniques that rely on specific markers are often helpful but may not always be available or practical for distinguishing between certain cell types. Additionally, distinguishing between similar cells in 3D imaging or volumetric data becomes even more complicated due to the challenge of interpreting the whole spatial structure.
Summary
Microscopic image labeling plays a critical role in modern biomedical research by enabling the accurate identification and analysis of cells, organelles, and pathogens. With advancements in microscopy techniques, the volume and complexity of images have increased, making annotation a time-consuming and error-prone task.
Machine learning models, especially those based on deep learning architectures, can further accelerate annotation by automatically identifying and labeling structures within images. Pre-trained models, fine-tuned with domain-specific data, allow for more efficient training, reducing the need for extensive labeled datasets.
Adequate image labeling through these combined strategies accelerates research, enhances diagnostic capabilities, and provides deeper insights into cellular functions and disease mechanisms.
FAQ
What is microscopic image labeling?
Microscopic image labeling involves annotating images of cells, organelles, or pathogens to identify and classify specific structures.
How do visual and marker-based differentiation help in labeling?
Visual differentiation relies on recognizing features like shape, size, and texture to distinguish structures. Marker-based differentiation uses fluorescent dyes or antibodies to tag specific molecules, making it easier to identify certain components, such as organelles or pathogens.
What is the role of machine learning in microscopic image annotation?
Machine learning models automate image annotation by learning patterns from labeled data. Algorithms like YOLO and Faster R-CNN detect and classify structures in new images, speeding up the labeling process.
Why is image pre-processing important in microscopic image labeling?
Image pre-processing corrects noise, uneven lighting, and poor contrast, making images more transparent and easier to analyze. It enhances the quality of images by applying techniques like noise reduction, contrast adjustment, and background subtraction.
What are consensus labels, and how are they used in training?
Consensus labels are created by combining annotations from multiple sources, such as different annotators or algorithms, to determine the most accurate label.
What challenges arise when distinguishing between similar cell types?
Similar cell types often have indistinguishable shapes, sizes, or structures, making it difficult to differentiate them under a microscope. Overlapping features, crowded cell arrangements, and limitations in imaging techniques can further complicate the process.
How can pre-trained models improve the annotation process?
Pre-trained models save time and computational resources by providing a strong foundation of learning features, which can be fine-tuned for specific microscopic images.


Comments ()