Software
"Data labeling software—also known as training data, data annotation, data tagging, or data classification software—provides a tool set for businesses to turn unlabeled data into labeled data and build corresponding artificial intelligence algorithms. Within these tools, the user inputs a given dataset and the software provides a label through machine learning-assisted labeling, a human taskforce, or the user themselves. Some platforms allow for the combination of the three, giving the user (or the system itself) the ability to choose who or what is doing the labeling, based on factors such as price, quality, and speed."
– G2.com

Top 7 trusted* global annotation providers in 2026
The research listing is based on the G2 Score of companies that offer 'Data Labeling Software'. These are the main objectives:
- identify the best of the reviews on the G2,
- for an understanding of any AI project budget, pricing information on their websites should be open and transparent.
| Company | G2 Score out of 5 | Pricing page |
| 1. SuperAnnotate | 4.9 | pricing page |
| 2. Keymakr with Keylabs Tool | 4.8 | pricing page |
| 3. V7 | 4.8 | pricing page |
| 4. Labelbox | 4.7 | pricing page |
| 5. Datasaur | 4.5 | pricing page |
| 6. Dataloop | 4.4 | no pricing page |
| 7. Appen | 4.1 | no pricing page |
LabelBox
An American company headquartered in San Francisco, California, was founded in 2017 by Brian Rieger, Daniel Rasmuson, and Manu Sharma. Labelbox is a collaborative platform for creating and managing labeled data for machine learning applications.
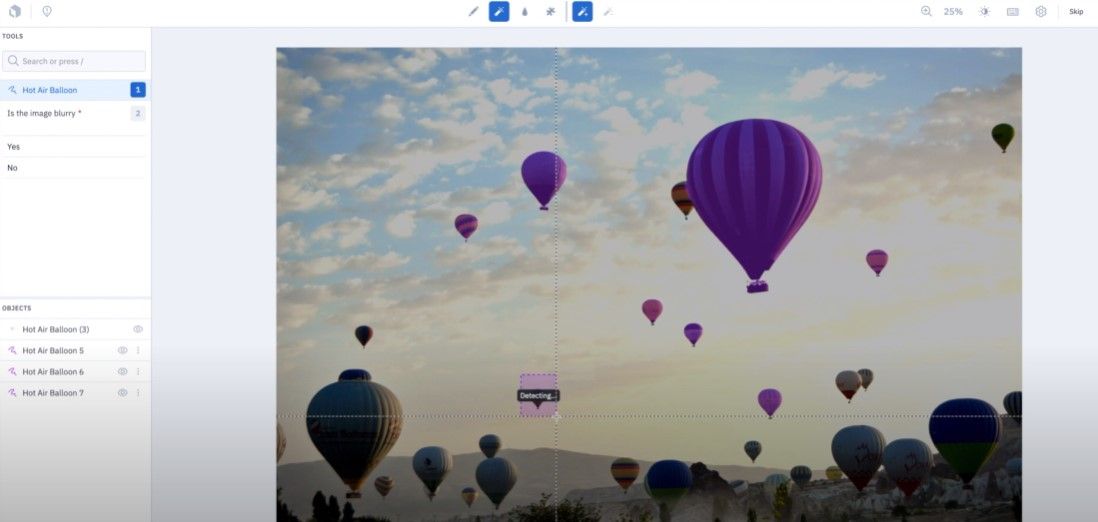
Labelbox is a collaborative platform for data training that creates and manages labeled data for machine learning applications. Labelbox provides a suite of features to assist with the development of machine learning applications, including auto-computed metrics for easier debugging of models. Their team of labeling operations experts has helped hundreds of AI teams set up, scale, and optimize their labeling process and has released a guide for best practices on the process.
The platform also offers a library, labelbox-bigquery, which makes it easy to process unstructured data and prepare it for analysis and AI work. The Labelbox Connector for Apache Spark takes in a Spark DataFrame and creates a dataset in Labelbox, and also brings labeled, structured data back into Apache Spark.
Keymakr
Keymakr offers high quality data creation, data annotation, and customer support services. Founded in 2015 by Arie Zilberman, Keymakr provides high-quality and affordable training data for computer vision-based artificial intelligence. The headquarter is located in Israel.
Keymakr is a data labeling company that provides services for image, document, and video annotation. Their core mission is to contribute to the development of transformative technology by creating high-quality data based on their clients' specifications. Keymakr offers professional data annotation for computer vision, utilizing cutting edge techniques to ensure accuracy and scalability.

Keylabs is Keymakr's Saas platform that provides high-performance features and unique management systems for data labeling. The platform has been built by annotation experts to deliver unique features and management systems for data labeling projects. It can be installed, set up, and supported on-premises and user roles and permissions can be assigned for each individual project or for platform access in general.
V7
In August 2018, V7 Darwin, a London-based startup, emerged from stealth mode to reveal a platform for labeling images for computer vision projects with minimal or no human intervention.

V7 Labs is a company that provides a platform for training and labeling data for artificial intelligence. V7 offers automated labeling tools, models in the loop, annotation services, and a powerful API. The company also provides resources and documentation to help users get started with its platform Darwin, including comprehensive guides and support. V7 has published a number of articles and best practices for preparing high-quality annotation guidelines, as well as a library for managing datasets.
The company also has a public library on GitHub, which includes tools for managing datasets and deep learning experiments.
Datasaur
Founded in 2019, the company is based in Sunnyvale, California. Datasaur manufactures data labeling tools that are designed to meet the needs of its customers. Using its specialized review tool, users can identify areas of disagreement between multiple teammates assigned to the same project.
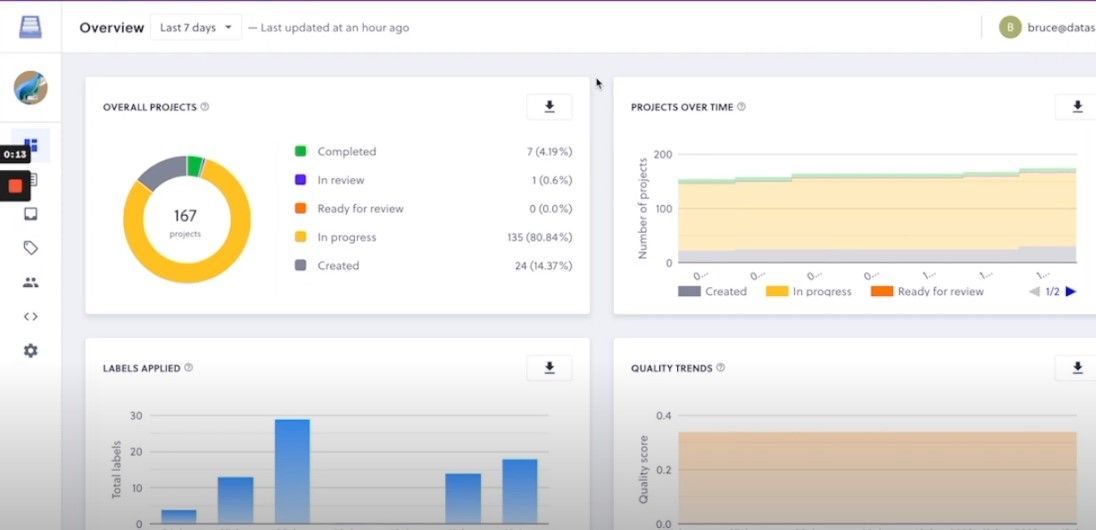
Datasaur offers an intelligent tool that uses AI and Natural Language Processing (NLP) to automate the data labeling process. Datasaur's platform helps manage the entire data labeling workflow with a single tool. It enables users to assign multiple teammates to the same projects and use its specialized review tool to quickly identify where they disagree. Its built-in intelligence catches costly errors. The platform is available for Cloud, Windows, Mac, and Linux and is suitable for organizations of all sizes.
Datasaur creates industry-leading solutions for text data labeling and is backed by YCombinator, Initialized Capital, and the CTO of OpenAI.
Dataloop
The DataLoop data management and annotation platform simplifies the process of preparing visual data for machine learning and deep learning.Dataloop is used to build and deploy powerful computer vision pipelines, such as data labeling, data operations automation, custom production pipelines, as well as human-in-the-loop data validation. Founded in 2017, the company is based in Herzliya, Tel Aviv.

Dataloop AI is a technology company that builds data infrastructure and a data operating system for AI companies. It offers a data management and annotation platform for AI teams to visualize, collaborate and explore datasets, build data pipeline automation processing, and combine human and machine intelligence.
The platform covers the entire data management cycle, from data labeling, automating data ops, deploying production pipelines, and weaving the human-in-the-loop. It streamlines the process of preparing visual data for machine and deep learning and is used for building and deploying powerful computer vision pipelines such as data labeling, automating data ops, customizing production pipelines, and human-in-the-loop data validation.
Dataloop's platform is a one-stop shop for generating datasets from unstructured data, and hosts multiple data management environments and intuitive annotation tools with automatic annotation.
SuperAnnotate AI
Armenian Start-up SuperAnnotate AI was founded by two brothers Tigran and Vahan Petrosyan in 2018. The SuperAnnotate platform provides tools for building training datasets for computer vision and natural language processing.
SuperAnnotate is a leading computer vision and AI company that offers cutting-edge image and video annotation services to businesses in various industries. The company has established a reputation as a provider of high-quality and accurate image and video annotation services and has quickly become a go-to solution for businesses looking to improve the performance of their machine learning algorithms.
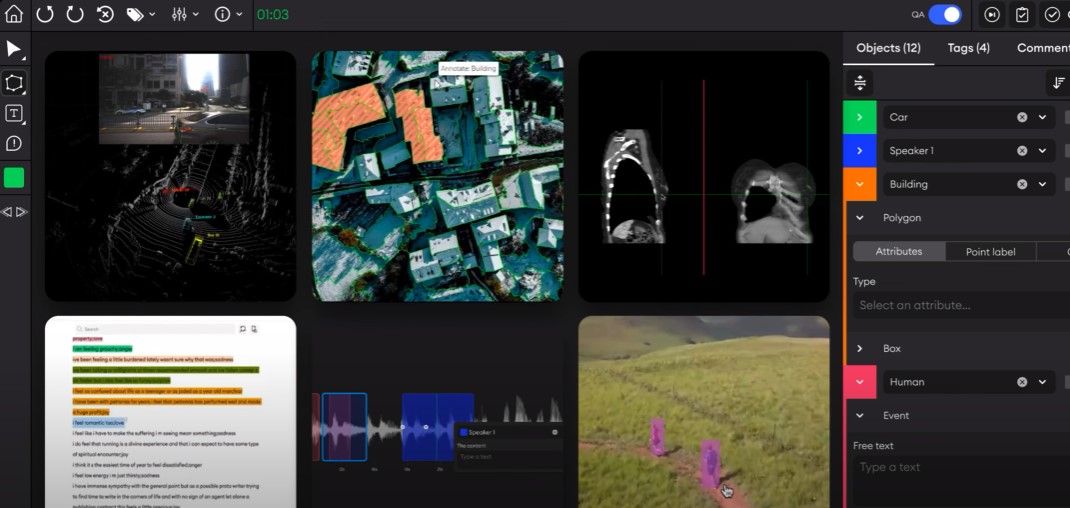
SuperAnnotate's platform is designed to be user-friendly and offers a range of powerful annotation tools, including object detection, semantic segmentation, and keypoint annotation. The platform also provides a centralized interface for managing annotations and projects, as well as real-time collaboration between annotators and project managers. This makes it easy for businesses to manage their image and video annotation projects, even if they have limited technical expertise.
Appen
Appen is a platform that collects and labels images, texts, speech, audio, video, and other data used in the development and improvement of artificial intelligence systems. The company offers a variety of services, including the evaluation of search media, the evaluation of social media, translations, and transcriptions.
Appen is a company that provides data collection and data annotation services to its customers. The company provides data collection services across various data types such as speech, text, image, video, and mixed data, which can be collected from various environments including studios, homes, offices, in-car, and public spaces. Appen has access to ethically sourced datasets for any use case through its global crowd of more than one million contributors.
Appen's data annotation platform (ADAP) works with a diverse set of formats, including audio, image, text, and video. The company's crowd is curated based on data annotation needs, and Appen selects the best contractors who match the skills required by the customer.
Related materials:
- Best Hardware for Machine Learning in 2023
- Unlock the World of Machine Learning: A Comprehensive Guide to the Top 15 Must-Read Books for Learners at All Levels in 2023