The role of image annotators in machine learning
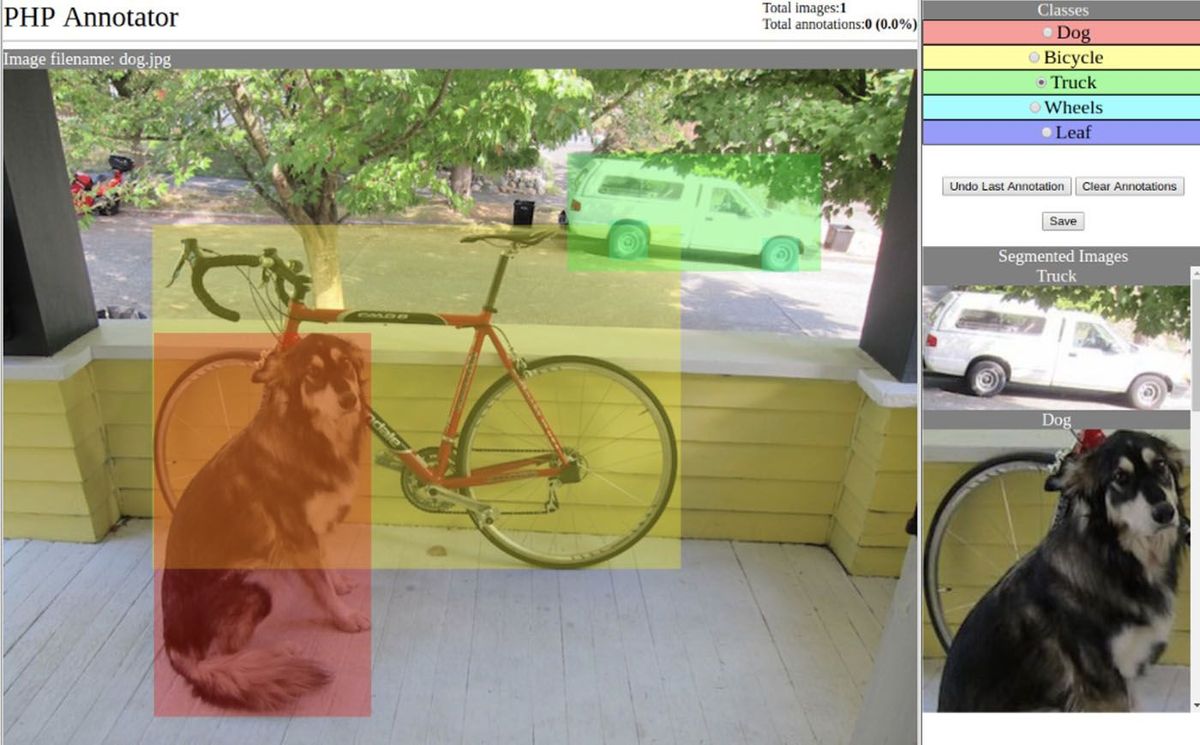
Image annotators are essential for the development of effective image recognition algorithms. Image annotation is the process of adding labeled contextual metadata to an image. This can enable a computer to recognize, classify, or describe the contents of inputs. The tools used to accomplish this can vary significantly. The type of data being collected and the intended outcomes drive this. It also depends on the team and budget available to you.
Understanding the different applications of image annotators is central to effective algorithms. The process of “teaching” a machine learning algorithm uses this training data to construct a version of reality for these machines. Annotators define this reality. Once the algorithms can reconstruct those definitions, they are said to be effective. Properly labeled data can establish a clear moment where this is the case.
Image annotation differs from other forms of data annotation because of the specific characteristics of image data. The sources of image data can vary significantly. Computer-generated imagery also complicates this process. At the end of the day, image annotation seeks to create a common language for these applications. They can transform the interpretation of images into an automated task. Image annotation is, in many ways, the basis for things like video annotation.
Why are image annotators important?
Image annotation in machine learning and computer vision applications rely on good annotators. They can improve the accuracy and performance of image recognition algorithms. They can provide needed context and information about the objects in an image. The goal of data annotators is to provide the tools to create a common language that can apply across projects.
Image annotators can also reduce the amount of data needed for training and testing these algorithms. Manual image labeling is a time-consuming and labor-intensive process. Using image annotators can help to automate and streamline this process. This can save time and resources and can make it easier and more efficient to develop and test image recognition algorithms.
Thirdly, image annotation can help improve image recognition algorithms' interpretability. Providing labels and metadata for objects in an image can make interpreting the results of an image recognition algorithm easier. Engineers validate these algorithms based on how accurate they are. Annotated data provides an objective baseline from which success or failure can be measured.
What are the most common forms of data annotators?
There are several different types of image annotation that can be performed. In each case, the form and function of the annotation process have specific uses. The specifics of these practices often depend on the software being used. File structures and data requirements often can vary by use case. Generally, they all seek to transform data in the same way. Some of the most common forms of image annotation include:
- Bounding box annotation
- Semantic segmentation
- Landmark identification
- Keypoint annotation
Bounding box annotation involves drawing a box around objects in an image. These boxes are then labeled with relevant information. This type of annotation can provide basic information about the objects in an image. It is most often used for the purposes of object detection and recognition. It is one of the most common kinds of image annotation formats. Most annotators allow for this to be done.

Semantic segmentation is a type of image annotation that involves dividing an image into labeled segments. Instead of labeling what things are, it tries to give context to what an image contains. It might identify relations between objects, for example. This can be critical in instances where placement or orientation is important. It provides a more detailed and accurate level of information about the objects in an image.
Landmark identification seeks to identify and label specific landmarks or points of interest in an image. It provides information about the location and orientation of objects in an image. It is most often used in applications such as mapping and navigation, where the location and orientation of objects in an image are crucial. It is an applied form of semantic segmentation. The contents of an image are used to infer more critical information. Embedding this in an algorithm allows for a more conceptual understanding of what place information is in a photo.
Keypoint image annotation tries to identify and label specific key points or features of objects in an image. This might include the shape and structure of objects in an image. It tries to not only what is there but what is important. Keypoint image annotation is often used in applications such as facial recognition or object tracking. For example, facial filters on social media can identify where eyes and noses are on faces. These key points provide another level of context to what is actually contained in images.
The future of image annotation
The future of image annotation is likely to be even more important for machine learning projects as the field continues to grow and evolve. As the use of machine learning and computer vision grows, so too will the demand for effective image recognition algorithms. Image annotation provides the necessary context and information for these algorithms to function. Effective image annotation tools will accelerate the rate at which new designs can be implemented.
One of the key developments in the future of image annotation is likely to be using more sophisticated methods. The types of image annotation that are needed changes as the technology develops. New image data sources mean that new kinds of tools will be required. They will reduce the amount of human input that will be required. The way that people use these tools will also change. Many of the tools used today already use AI to reduce the workload for users.
Of course, the tools used only constitute one part of the algorithm design process. Planning will still be required in other aspects of your project. Tools will likely incorporate more of these phases as they become more advanced. A strong grasp of how your data can be best annotated is still central. There is no one-size-fits-all version of this process. Just like the algorithms, annotators reflect the intentions of their operators. Understanding the tools being used is the major responsibility of development teams.



Comments ()